
Are LMMs Robust to Small Image Perturbations?
Published:
Huge foundation models allow us to solve many tasks without training a task-specific model. For example, Large Language Models (LLMs) excel at predicting the next word in a text. This allows us to use them for a variety of tasks, including code generation and automatic text summarization.
Large Multimodal Models (LMMs) further extend the capabilities of LLMs, as they can also process images or other data modalities in addition to text. Naturally, we can use LMMs to solve computer vision tasks without the need for additional training data. For example, we can use LMMs to classify images (as also demonstrated below).
We are curious whether LMMs do this in a robust way: ideally, small perturbations of an input image should not change the predictions of LMMs. In this blog post (and accompanying code) we explore whether this is the case.
Image classification with LMMs
LLMs allow providing both text and images to a model. This makes it very easy to solve many computer vision tasks using the model: We can simply describe the task in natural language, and provide this description to the model along with an image. Then we ask the model to provide an output, again using natural language.
For this blog post, we consider the task of classifying an input image into 1 out of 10 possible categories based on its content. We choose to provide the following prompt to the model in addition to the image:
<|user|> This image shows either a plane, car, bird,
cat, deer, dog, frog, horse, ship or truck.<|image_1|>
Which one is it? <|end|><|assistant|>It shows a
Here, <|user|>, <|end|> and <|assistant|> are special formatting tokens and <|image_1|> is a placeholder for the image encoding.
With this prompt, we use the LMM to produce a single additional word. We then directly consider this word as the category predicted by our model.
We test the model Phi-4-multimodal-instruct 1, provided at huggingface. It is based on a 3.8 billion parameter LLM and uses additional 810 million parameters for the image encoding and a vision adapter.
We evaluate the model on the CIFAR-10 dataset, consisting of tiny resolution (\(32 \times 32\)) images from 10 categories.
Classification Results
As a first positive result, we observe that the LMM almost always responds with one of the provided categories. Only very rarely the model generates a synonym, such as “boat”, or a completely different category (e.g. “ghost”). We consider these as wrong predictions.
In our setup, Phi-4-multimodal generates correct predictions on \(86.9\%\) of our validation examples. This is an acceptable result considering there was no prompt optimization or fine-tuning. The accuracy is clearly worse than the \(\sim 94\%\) we can get with a small model trained for a few minutes on CIFAR-10, but it seems reasonable in this zero-shot setting, especially considering that the LMM is probably not trained on many images with such a low resolution.
Below we show a few predictions by the model that we consider wrong predictions:



Are LLMs robust?
In order to test the robustness of Phi-4-multimodal, we could directly try to create adversarial perturbations that fool the model. For this blog post, I decided to do a computationally cheaper approach: Create adversarial examples for a small convolutional model, and evaluate whether those transfer to the LMM.
As the convolutional model we use our SimpleConvNet, trained to about \(93.3\%\) validation set accuracy in a few minutes. For this model, the Fast Adaptive Boundary Attack 2 (in the implementation from 3) very successfully generates adversarial examples. The attack aims to find adversarial perturbations with minimal L2-norm. However, instead of minimizing the norm, we want adversarial examples for which the model very confidently predicts a wrong class, so that they are more likely to transfer to another model. We achieve this by doing a few gradient ascent steps starting from the original adversarial examples found by the Fast Adaptive Boundary Attack. For details on our full attack see our code 4. For the SimpleConvNet, our attack causes an accuracy below chance level already for perturbations with L2 norm \(\le 0.3\).
LMMs Robustness Results
Now it’s time to answer our original question: Are LLMs robust to small image perturbations? The answer turns out to be no. Even attacks constructed for a very different model can fool Phi-4-multimodal, as quantified in the following plot:
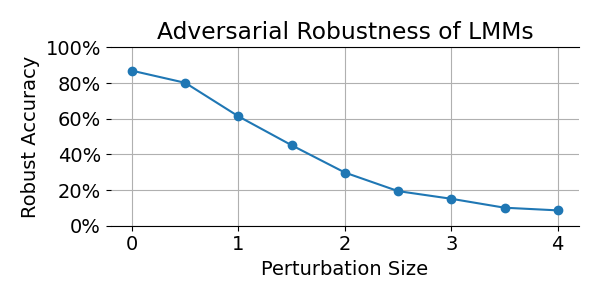
Note that we do seem to require larger perturbations in order to fool the LMM compared to the ConvNet. However, the plot above shows only an upper bound to the adversarial robustness. There probably exist much smaller perturbations that fool the model, they might just be a bit harder to find. Also, it is remarkable that the adversarial examples transfer to the LMM at all, as this requires them to “survive” image transformation such as conversion to int8 and image resizing.
Below we visualize some of the adversarial examples that fool Phi-4-multimodal. We always show the original image (left) and the perturbed version (right) side-by-side, both with the model prediction below. In these examples the perturbations have L2 norm \(\le 2\). Note that some of the perturbations actually semantically change the images. For these case we can’t really blame the LMM for generating the wrong predictions.









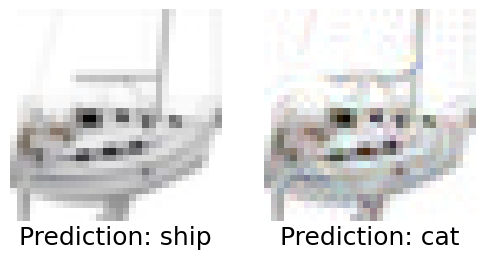


Conclusion
Classifying low-resolution images using a Large Multimodal Model is a bit like cracking a nut with a sledgehammer — but even this simple task reveals meaningful limitations. Our experiments show that LMMs are vulnerable to small input perturbations, suggesting that their apparent versatility doesn’t guarantee robustness. Notably, adversarial examples generated for a small ConvNet not only transfer effectively to the LMM, but also withstand various image transformations along the way.
Our findings highlight a key challenge in deploying LMMs for real-world vision tasks: ensuring resilience against small adversarial manipulations. As foundation models continue expanding across modalities, understanding their vulnerabilities is crucial for ensuring their security.
Microsoft (2025). Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras ↩
Matthias Hein and Francesco Croce (2019). Minimally distorted Adversarial Examples with a Fast Adaptive Boundary Attack ↩
Hoki Kim (2015). Torchattacks: A pytorch repository for adversarial attacks. ↩
Bernd Prach (2025). https://github.com/berndprach/LMM_Robustness ↩
 In our recent CVPR paper,
In our recent CVPR paper,