How Many Power Iteration Steps do 1-Lipschitz Networks Need?
Published:
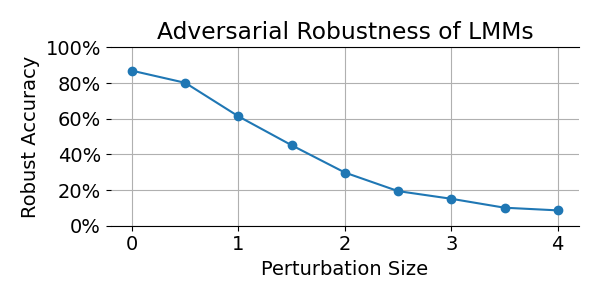
Power iteration is a widely used algorithm for constructing 1-Lipschitz layers. In this blog post we explore how many steps are required to obtain reliable guarantees. The takeaway? It’s far more than most papers assume. 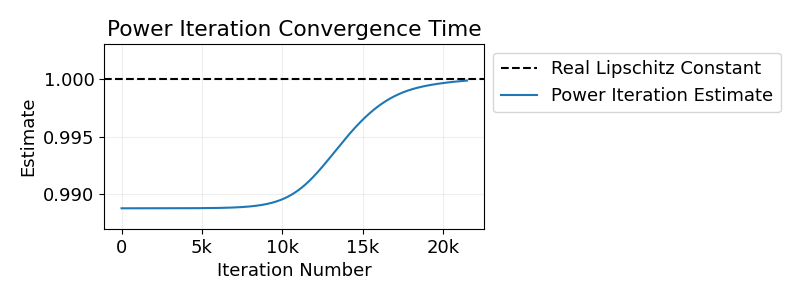
 In our recent CVPR paper,
In our recent CVPR paper,